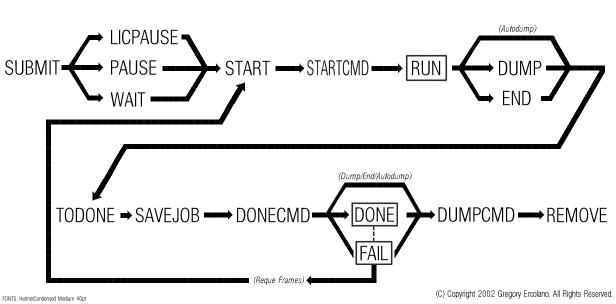
Rush Command Line Options
A description of all the 'rush' command line flags.
|
|
-ac
|
Add Cpus, adds to job cpus to use for rendering
|
|
-af
|
Add Frames, adds new frames to a job
|
|
-an
|
Add Nevercpus, adds to job names of cpus to never use
|
|
-autodump
|
Automatically dump job on completion (done|donefail|-)
|
|
-catlog
|
Views the remote daemon's log files (New in 102.42)
|
|
-checkconf
|
Checks a rush.conf file for errors
|
|
-checkhosts
|
Checks a rush hosts file for errors
|
|
-command
|
Sets job's command to run each frame
|
|
-cont
|
Continue a paused job
|
|
-cp
|
Change Priority for job's existing cpus
|
|
-criteria
|
Sets criteria qualifiers for the job
|
|
-d
|
Enable debugging in rush client
|
-dcatlog
|
Views the remote daemon's log file (replaced by -catlog)
|
|
-deltaskfu
|
Deletes a task from a job or from a cpu server
|
|
-dexit
|
Tells a daemon to exit immediately via TCP
|
|
-dexitnow
|
Tells a daemon to exit immediately via UDP
|
|
-dependon
|
Makes a job dependent on frames in other job(s)
|
|
-dlog
|
Enables certain daemon debug logging flags
|
|
-dlogstats
|
Checks daemon logs for errors
|
|
-done
|
Changes frames into the Done state
|
-donecommand
|
Sets command to run when job is done (replaced by -jobdonecommand)
|
|
-donemail
|
Sets who to email when job is done
|
|
-down
|
Tells rush a machine is down.
|
|
-dump
|
Dumps a job, kills running frames
|
|
-dumpmail
|
Sets who to email when job is dumped
|
|
-end
|
Ends a job, lets running frames complete
|
|
-exitnotes
|
Pass exit notes back on frame completion
|
|
-fail
|
Changes frames into the Fail state
|
|
-fu
|
Allows you to change other people's jobs
|
|
-getoff
|
Kills renders, offlines the cpus
|
|
-hold
|
Changes frames into the Hold state
|
|
-imgcommand
|
Sets the command irush uses to display images
|
|
-jobcheckpoint
|
Causes daemon to update the jobcheckpoint file
|
|
-jobnotes
|
Changes the notes for the job
|
|
-jobremarks
|
Add custom messages to the -lj/-laj 'Remarks' field.
|
|
-jobstartcommand
|
Changes the command executed when job starts
|
|
-jobdonecommand
|
Changes the command executed when job done
|
|
-jobdumpcommand
|
Changes the command executed when job dumps
|
|
-lac
|
List All Cpus, lists status of all cpus on the net
|
|
-lacf
|
List All Cpus Full, full report
|
|
-lah
|
List All Hosts, showing #cpus, ram, criteria, hostgroups
|
|
-lahf
|
List All Hosts Full, full report
|
|
-laj
|
List All Jobs, all jobs on the network
|
|
-lajf
|
List All Jobs Full, full report
|
|
-lc
|
List Cpus, all cpus requested by a job
|
|
-lcf
|
List Cpus Full, full report
|
|
-lf
|
List Frames, shows the job's frame list
|
|
-lff
|
List Frames Full, full report
|
|
-lfi
|
List Frame Info, a short report of render statistics
|
|
-lhc
|
List Host Criteria
|
|
-lhg
|
List Host Groups
|
|
-lj
|
List Jobs. Lists jobs on local or remote host(s)
|
|
-ljf
|
List Jobs Full, full report
|
|
-licpause
|
Pause job for short period, due to license error
|
|
-licpausesecs
|
Set pause time for -licpause
|
|
-log
|
Shows the log file for frame(s) in job(s)
|
|
-logdir
|
Sets the directory log files are written
|
|
-logext
|
Changes the log filename extensions (.txt)
|
|
-logflags
|
Changes the job's logging flags (keepall|keeplast|-)
|
|
-maxcpus
|
Sets maximum number of cpus a job can use
|
|
-maxtime
|
Sets maximum time for rendering frames
|
|
-maxtimestate
|
Behavior when maxtime elapses
|
|
-nice
|
Set job's unix nice(1) value
|
|
-notes
|
Changes notes field for specified frame(s)
|
|
-offline
|
Offlines the local or remote host from rendering
|
|
-online
|
Onlines the local or remote host for rendering
|
|
-pause
|
Pauses the job
|
|
-ping
|
Pings the local or remote rush daemon(s) using TCP
|
|
-priority
|
Changes the default priority value
|
|
-push
|
Push rush administration files out to network
|
|
-que
|
Requeues a frame
|
|
-ram
|
Changes the job's ram use value
|
|
-ramlist
|
Show the ram use of all processors on remote host
|
|
-rc
|
Removes a cpu from the current job
|
|
-reorder
|
Reorders the frames in the frame list
|
|
-reload
|
(Admin) Force reload of hosts or rush.conf files, flushing caches. (New in 102.42)
|
|
-reserve
|
Reserves cpus on local or remote machines
|
|
-rf
|
Removes frames from the frame list
|
|
-rn
|
Removes 'nevercpus'
|
|
-rotate
|
Rotates the local or remote daemon's log file (added features in 102.42)
|
|
-status
|
Status of jobs and cpus on local or remote hosts (added features in 102.42)
|
|
-submit
|
Submits a job
|
|
-tasklist
|
Shows the list of scheduled tasks on local or remote host
|
|
-title
|
Changes the title of the job
|
|
-trs
|
Shows the Template Render Script
|
|
-try
|
Changes the Try count for frame(s)
|
|
-tss
|
Shows the Template Submit Script
|
|
-uping
|
Pings the local or remote rush daemon(s) using UDP
|
|
-waitfor
|
Make a job Wait For other jobs or times
|
|
-waitforstate
|
Controls what circumstances cause the WaitFor trigger.
|